

이번 글에서는 아래 그림과 같이 Hadoop MapReduce를 이용한 word count 실습에 대해 포스팅할 예정이다.
MapReduce에 대한 설명은 아래 링크에서 확인할 수 있다.
실습에 사용한 환경
본 글에서 설명하는 실습은 다음과 같은 환경에서 진행하였다.
| OS | Ubuntu 20.04 |
| Java | openjdk-11-jdk |
| Hadoop | hadoop-3.4.0 |
| IDE | Visual Studio Code |
실습 시작
실습에 큰 흐름은 다음과 같다.
1. HDFS에 txt 파일 저장
2. MapReduce 코드 작성
3. jar 파일 생성
4. 실행
5. 결과 확인
1. HDFS에 txt 파일 저장
이 단계에서는 단어를 세고 싶은 txt 파일을 HDFS에 업로드한다.
본인은 Idina Menzel의 Let it go 라는 노래의 가사를 txt 파일로 만들고 HDFS에 업로드했다.
HDFS에 파일을 업로드하는 명령어는 hdfs dfs -put 이다. 다음과 같이 사용할 수 있다.
$ hdfs dfs -put <file> <hdfs path>
- <file>에는 업로드하고 싶은 파일의 경로를 넣어주면된다.
- <hdfs path>에는 파일을 저장하고 싶은 hdfs 경로를 넣어주면된다.
예를 들어, 다음과 같이 사용할 수 있다.
$ hdfs dfs -put Let_it_go.txt /wordcount_example
잘 업로드가 됐는지 확인하려면 hdfs dfs -ls 명령어를 사용하면된다. -ls 뒤에는 원하는 hdfs 경로를 넣어주면된다.
$ hdfs dfs -ls /wordcount_example
그림을 보면 정상적으로 업로드된 것을 확인할 수 있다.
기회가 되면 hdfs 명령어에 대한 글도 포스팅해봐야겠다.
<namenode>:9870에 접속해서 웹 UI로도 확인할 수 있다.
업로드한 Let_it_go.txt 파일이 SN09와 SN06, SN01에 복제되어 저장되어 있음을 확인할 수 있다.
2. MapReduce 코드 작성
코드 작성은 vs code에서 진행하였다.
또한, jar파일을 생성해야하기 때문에 Maven을 사용하였다.
2. 1. Java Project 생성 (Maven)
vs code에서 F1(Mac은 cmd + shift + p)을 눌러 Java: Create Java Project...을 선택한다.
여러가지가 나올텐데 Maven을 선택해준다.
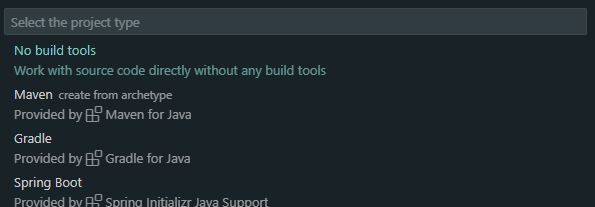
maven-archetype-quickstart를 선택해준다.
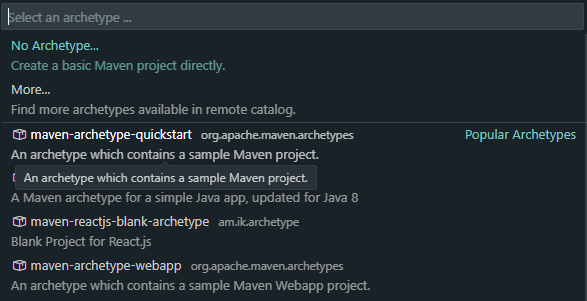
1.4를 선택해준다.
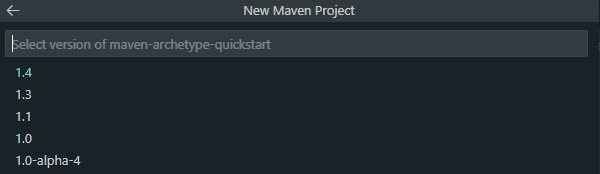
다음으로 group Id와 arifact Id를 설정한다.


마지막으로, 원하는 경로를 지정한다.

완료되면 지정한 경로에 다음과 같이 생성이 된다.
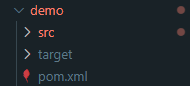
2. 2. pom.xml 설정
pom.xml에 hadoop 의존성을 추가해야한다.
<properties>
<hadoop.version>3.4.0</hadoop.version>
</properties><dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.4.0</version>
</dependency>
</dependencies>
설치된 hadoop에 맞는 version을 기입해야한다.
2. 3. WordCountMapper.java 코드 작성
위 경로(main/java/com/example)에 WordCountMapper.java를 생성후, 코드를 작성한다.
package com.example;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] tokens = value.toString().split("\\s+");
for (String token : tokens) {
if (token.matches("[a-zA-Z]+")){
token = token.toLowerCase();
}
word.set(token);
context.write(word, one);
}
}
}
이는 Map 단계에 역할을 수행한다.
입력 데이터를 키-값 쌍으로 변환하는 작업을 수행한다.
또한, 텍스트 데이터를 단어별로 분리해 각 단어를 키로, 값으로는 정수 1을 write한다.
이때, 단어가 영어라면 소문자로 변환한다.
예: "Hello world hello" → [(hello, 1), (world, 1), (hello, 1)]
2. 4. WordCountReducer.java 코드 작성
WordCountMapper.java와 마찬가지로 위 경로에 WordCountReducer.java를 생성후, 코드를 작성한다.
package com.example;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
이는 Reduce 단계에 역할을 수행한다.
Map 단계의 출력 결과를 받아 동일한 키(단어)를 가진 값을 그룹화하여 합산한다.
최종적으로 단어와 등장 횟수를 write한다.
예: [(hello, 1), (world, 1), (hello, 1)] → [(hello, 2), (world, 1)]
2. 5. WordCountDriver.java 코드 작성
마찬가지로 위 경로에 WordCountDriver.java를 생성후, 코드를 작성한다.
package com.example;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); // Hadoop 설정 객체 생성
Job job = Job.getInstance(conf, "word count"); // job 이름 설정
job.setJarByClass(WordCountDriver.class); // jar 파일 클래스 지정
// Mapper와 Reducer 클래스 지정
job.setMapperClass(WordCountMapper.class);
job.setCombinerClass(WordCountReducer.class);
job.setReducerClass(WordCountReducer.class);
// 키와 값의 데이터 형식 지정
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 입력 및 출력 경로 설정
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
이는 Hadoop 작업을 설정하고 제출한다.
또한 Map과 Reduce 클래스, 입력 및 출력 경로, 데이터 형식등을 지정한다.
간단하게 주석에 각 코드가 하는 일을 적어 놓았다.
모두 완료 하면 아래 그림과 같이 저장되어 있을 것이다.
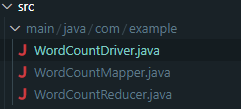
3. jar 파일 생성
이제 Maven을 이용해 코드를 컴파일하고, 실행 가능한 jar 파일을 생성해보자
$ mvn clean complie package
아무 문제 없이 완료 되었다면 target 디렉토리에 jar파일이 생성되어 있을 것이다.

4. 실행
이제 이를 실행해보자!
명령어는 다음과같다.
$ hadoop jar target/wordcount-1.0-SNAPSHOT.jar com.example.WordCountDriver <HDFS Input data 경로> <결과를 저장할 HDFS 경로>
본인은 다음과 같이 진행했다.
$ hadoop jar target/wordcount-1.0-SNAPSHOT.jar com.example.WordCountDriver /wordcount_example/Let_it_go.txt /wordcount_example/output
정상적으로 실행됨을 확인할 수 있다.
5. 결과 확인
hdfs dfs -ls 명령어를 통해 결과 파일이 저장되었는지를 확인한다.
$ hdfs dfs -ls <결과를 저장한 hdfs 경로>
본인은 다음과 같이 명령어를 실행했다.
$ hdfs dfs -ls /wordcount_example/output
잘 저장된 것을 확인할 수 있다.
cat을 통해 결과를 확인해보자
$ hdfs dfs -cat /wordcount_example/output/part-r-00000
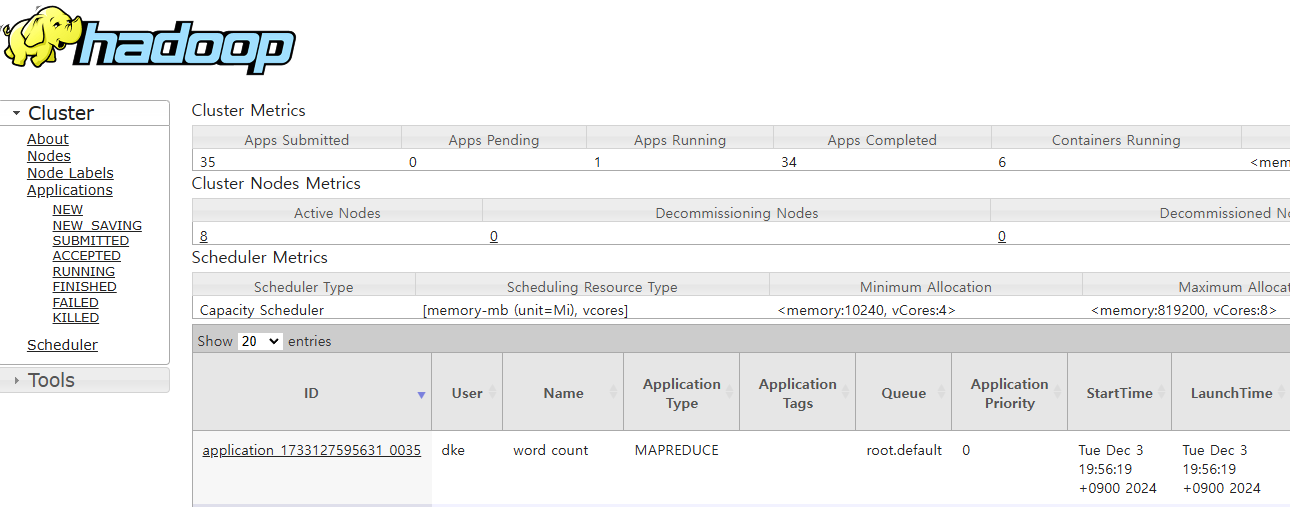
8088 포트의 웹 UI에서도 진행된 application에 대해 확인할 수 있다.
마무리
이번 글에서는 Hadoop MapReduce를 이용한 Word Count 실습에 대해 소개하였다.
MapReduce가 실제로 어떻게 동작하는지 알 수 있었던 것 같다.
실습에 관한 코드는 github에도 올려놓았으니 필요하신분들은 사용하시길 바란다.
'Data Engineering > Hadoop' 카테고리의 다른 글
| [Hadoop] Apache Hadoop 설치 (1) | 2024.12.03 |
|---|---|
| [Hadoop] MapReduce와 YARN (0) | 2024.12.02 |
| [Hadoop] HDFS란? (0) | 2024.12.01 |
| [Hadoop] Apache Hadoop 소개 (0) | 2024.11.24 |