

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- docker
- 아파치 하둡
- 파이썬
- 알고리즘
- 이진탐색
- 스파크
- programmers
- heapq
- 빅데이터
- 오블완
- 하둡
- Python
- Hadoop
- 아파치 스파크
- 프로그래머스
- 분산처리
- 분산
- Apache Hadoop
- 티스토리챌린지
- 딕셔너리
- Spark
- Data Engineering
- 리트코드
- 도커
- HDFS
- 데이터 엔지니어링
- Apache Spark
- 코딩테스트
- leetcode
- 우선순위큐
- Today
- Total
래원
[Hadoop] Apache Hadoop 설치 본문

이번 글에서는 Hadoop 설치 과정에 대해 소개 할 예정이다.
글 시작하기에 앞서, 이전 글들을 보고 오는 것을 추천한다.
버전 정보
본 글에서 사용하는 환경은 다음과 같다.
OS: Ubuntu 20.04
Java: openjdk-11-jdk
Hadoop: Hadoop 3.4.0
Java 설치
Hadoop은 Java 기반으로 개발되었다.
따라서, Hadoop의 실행과 관련된 모든 프로세스는 Java로 작성된 프로그램이므로 Java를 먼저 설치해주어야한다.
사용할 모든 노드에서 설치를 진행해야 한다.
$ sudo apt update
$ sudo apt list openjdk* # 모든 버전 목록 조회
$ sudo apt install openjdk-11-jdk # 원하는 버전 설치
잘 설치 됐는지 확인하기 위해서 java -version 명령어를 사용한다.
$ java -version
SSH 설정
Hadoop은 노드 간 통신과 협력이 필요하기 때문에 SSH 설정을 필수적으로 해야한다.
Hadoop 설치 전에 SSH를 올바르게 설정해야 클러스터를 원활히 구성할 수 있다.
먼저, 사용할 모든 노드의 /etc/hosts 파일에 사용할 노드들의 IP와 이름을 지정해준다.
$ sudo vim /etc/hosts # 사용할 모든 노드에서
<IP> <NAME>
<IP> <NAME>
.
.
.
<IP> <NAME>
그리고 사용할 모든 노드에서 root로 접속해 /etc/ssh/sshd_config 파일을 수정해준다.
$ sudo su
vim /etc/ssh/sshd_config
PermitRootLogin no # yes로 변경
...
PasswordAuthentication no # yes로 변경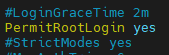

그 후 exit 명령어로 root 계정을 빠져나온다.

SSH를 재실행 해준다.
$ systemctl restart sshd
그런 다음 마스터노드에서만 다른 노드들에 접근할 수 있게 키를 저장한다.
$ ssh-copy-id -i ~/.ssh/id_rsa.pub dke@SN01
$ ssh-copy-id -i ~/.ssh/id_rsa.pub dke@SN02
$ ssh-copy-id -i ~/.ssh/id_rsa.pub dke@SN03
$ ssh-copy-id -i ~/.ssh/id_rsa.pub dke@SN04
...
$ ssh-copy-id -i ~/.ssh/id_rsa.pub dke@SN09
만약 22번 포트를 사용하지 않는다면 명령어 마지막에 -p <Port> 을 붙여주면된다.
Hadoop 설치

https://downloads.apache.org/hadoop/common
Index of /hadoop/common
downloads.apache.org
위 사이트에서 원하는 Hadoop 버전을 다운 받을 수 있다.

본 글에서는 Hadoop 3.4.0을 사용했기 때문에 hadoop-3.4.0.tar.gz 다운 링크를 복사해 wget 함수를 통해 받아왔다.
이 역시 사용할 모든 노드에서 수행해야 한다.
$ # 모든 서버에서
$ wget https://downloads.apache.org/hadoop/common/hadoop-3.4.0/hadoop-3.4.0.tar.gz
$ tar -xvzf hadoop-3.4.0.tar.gz # 압축풀기
$ (sudo) ln -s hadoop-3.4.0 hadoop # 심볼릭 링크 생성
위 명령어들을 실행하면 위 그림과 같이 저장되어 있을 것이다. 아래 명령어를 통해 hadoop version을 확인할 수 있다.
$ hadoop version
환경 변수 설정
다음으로 환경 변수를 설정해주어야 한다.
# 모든 서버에서
sudo vim ~/.bashrc
다음을 추가한다.
export HADOOP_HOME=<Hadoop 설치한 경로>
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HADOOP_HOME/lib/native
저장하고 나와서 source ~/.bashrc를 수행한다.
# 모든 서버에서
source ~/.bashrc
Hadoop JAVA_HOME 설정
다음으로, hadoop-env.sh 스크립트에서 JAVA_HOME 환경 변수를 구성해야한다.
JAVA_HOME 행의 주석을 해제하고 Java OpenJDK 설치 디렉토리로 변경한다.
# 모든 서버에서
vim $HADOOP_HOME/etc/hadoop/hadoop-env.shexport JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
Hadoop Workers 이름 명시
worker 노드로 사용할 노드들의 이름을 명시한다.
# 마스터 노드에서만
vim $HADOOP_HOME/etc/hadoop/workers
<NAME>
<NAME>
<NAME>
.
.
.
<NAME>
core-site.xml 설정
# 모든 서버
vim $HADOOP_HOME/etc/hadoop/core-site.xml
위 그림과 같이 추가해준다. 위 설정은 HDFS를 기본 파일 시스템으로 사용하며, MN:9000이 NameNode의 주소임을 나타낸다.
hdfs-site.xml 설정
# 모든 서버
vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
위 그림과 같이 추가해준다.
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
위 설정은 HDFS에 저장될 데이터의 복제본 개수를 3개로 지정한다.
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>SN01:9868</value>
</property>
위 설정은 Hadoop 클러스터에서 Secondary NameNode가 제공하는 웹 인터페이스에 액세스할 때 사용되는 주소와 포트를 지정한다.
<property>
<name>dfs.namenode.name.dir</name>
<value>file:<경로>/hadoopdata/hdfs/namenode</value>
</property>
위 설정은 NameNode의 메타데이터 저장 경로를 지정한다.
<property>
<name>dfs.datanode.data.dir</name>
<value>file:<경로>/hadoopdata/hdfs/datanode</value>
</property>
위 설정은 DataNode가 실제 데이터 블록을 저장하는 경로를 지정한다.
mapred-site.xml 설정
# 모든 서버
vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
위 그림과 같이 추가해준다.
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
위 설정은 MapReduce 프레임워크를 YARN을 사용하도록 지정한다.
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
위 설정은 MapReduce 작업에서 사용될 클래스 경로(classpath)를 설정한다.
yarn-site.xml
# 모든 서버
vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
각 설정에 대한 설명은 다음과 같다.
# MapReduce Shuffle 활성화
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
# 환경 변수 목록으로, NodeManager가 실행할 때 허용된 환경 변수만 사용할 수 있도록 제한
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
# YARN 클러스터에서 ResourceManager 지정. 본 설정에서는 MN으로 설정
<property>
<name>yarn.resourcemanager.hostname</name>
<value>MN</value>
</property>
# NodeManager에서 각 컨테이너에 할당할 수 있는 최대 메모리 설정
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>819200</value>
</property>
# NodeManager에서 사용할 수 있는 가상 CPU 코어 수 설정
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>8</value>
</property>
# YARN 스케줄러가 컨테이너에 할당할 수 있는 최소 vCore 수 설정
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>4</value>
</property>
# YARN 스케줄러가 컨테이너에 할당할 수 있는 최대 vCore 수 설정
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>16</value>
</property>
# YARN 스케줄러가 컨테이너에 할당할 수 있는 최소 메모리 크기
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>10240</value>
</property>
# YARN 스케줄러가 컨테이너에 할당할 수 있는 최대 메모리 크기
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>819200</value>
</property>Hadoop 실행
기본적인 설정은 끝났으니 이제 실행해보자
# 모든 서버 방화벽 해제
systemctl stop firewalld 또는 systemctl disable firewalld
# 마스터 노드에서만
$HADOOP_HOME/bin/hdfs namenode -format # Hadoop foramt (최초 한번만 실행)
$HADOOP_HOME/sbin/start-all.sh #Hadoop 실행
정상적으로 실행됐는지 확인해보자
jps
jps는 실행 중인 Java 프로세스를 보여주는 유틸리티이다.
Hadoop은 여러 Java 기반 데몬으로 구성되기 때문에 jps 명령어를 통해 빠르게 확인할 수 있다.
MN

NameNode와 ResourceManager가 정상적으로 실행중인 것을 확인할 수 있다.
SN01

DataNode와 NodeManager를 비롯해 Secondary NameNode도 정상적으로 실행중인 것을 확인할 수 있다.
SN02 ~ SN09
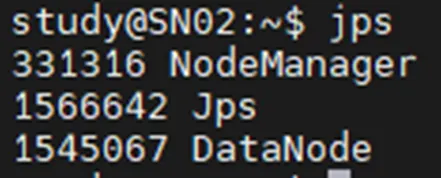
DataNode와 NodeManager가 정상적으로 실행중인 것을 확인할 수 있다.
HDFS 동작 확인
# 마스터 노드에서
hdfs dfs -ls /
hdfs / 경로에 저장된 파일을 확인할 수 있다.

# 마스터 노드에서
touch temp.txt
hdfs dfs -put temp.txt /
hdfs dfs -ls /

정상적으로 temp.txt 파일이 hdfs의 / 경로에 저장된 것을 확인할 수 있다.
또한, 9870포트로 접속해 HDFS 마스터노드 웹 UI를 확인할 수 있고, 8088포트로 접속해 YARN ResourceManger 상태와 실행 중인 작업 등을 제공하는 웹 UI를 확인할 수 있다.
마무리
이번 글에서는 Hadoop 설치 과정에 대해 알아보았다.
설치 과정이 굉장히 복잡하지만, 정상적으로 동작하는 모습을 보면 쾌감이 느껴지는 것 같다.
다음에는 간단한 실습에 대해 포스팅할 예정이다.
'Data Engineering > Hadoop' 카테고리의 다른 글
| [Hadoop] Hadoop MapReduce를 이용한 Word Count 실습 (3) | 2024.12.03 |
|---|---|
| [Hadoop] MapReduce와 YARN (0) | 2024.12.02 |
| [Hadoop] HDFS란? (0) | 2024.12.01 |
| [Hadoop] Apache Hadoop 소개 (0) | 2024.11.24 |



