
이번 글에서는 MapReduce와 YARN에 대해 알아보자
이전 글과 이어지니 보고오는 것을 추천한다.
What is MapReduce?

MapReduce는 2004년 Google에서 처음 제안한 대용량 데이터 처리 모델로, 분산 환경에서 데이터 처리 작업을 쉽게 수행할 수 있도록 설계되었다.
이러한 MapReduce는 HDFS에 저장된 대규모 데이터를 효율적으로 분석하고 처리할 수 있게 도와준다.
이름에서 볼 수 있듯 Map과 Reduce라는 두 단계로 나뉘게 된다.
Map
- 입력 데이터를 키-값 쌍으로 변환하여 병렬 처리가 가능하도록 데이터 구조를 단순화 하는 작업
- 예를 들어, 위 그림에서는 각 단어를 키로 하고, 출현 횟수를 값으로 매핑
- Map 단계에서 다루는 Input 데이터는 서로 다른 HDFS에 저장된 블록 데이터
Reduce
- Shuffle: Map 단계의 결과를 정렬하고 그룹화하여 같은 키를 가진 데이터를 모음
- Shuffle 단계에서 전달 받은 데이터를 기반으로 연산(합계, 평균 등) 수행
- 예를 들어, 위 그림에서는 같은 단어를 그룹화하고, 출현 횟수를 모두 합함
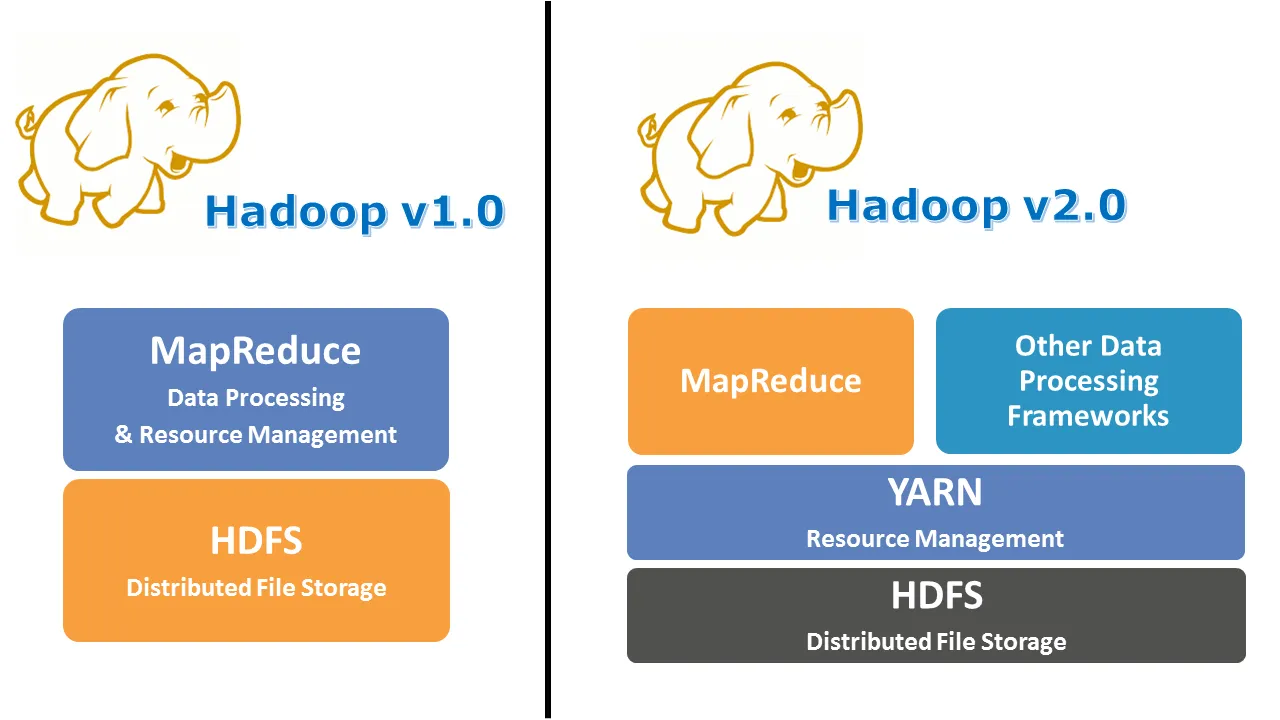
MapReduce Architecture (Hadoop v1.0)

Hadoop v1.0에서는 작업의 처리와 자원의 관리를 함께 수행하는 JobTracker와 TaskTracker라는 두 가지 주요 요소를 사용하여 MapReduce 작업을 처리했다.
Job은 Client가 수행하려고 하는 작업 단위로 이해하면 된다.
각각 JobTracker와 TaskTracker는 다음과 같다.
JobTracker
- 클러스터에서 실행되는 MapReduce 작업을 관리하고, 자원 할당 및 작업 스케줄링을 담당
- Client가 제출한 Job을 처리할 노드를 결정하고, Job의 실행 상태를 모니터링
- Job을 여러 TaskTracker 노드로 분할(Map 및 Reduce 작업 분배)
- Job 진행 상황을 추적하며, 실패한 Job을 재실행
TaskTracker
- JobTracker로부터 할당받은 Job을 실제로 실행
- Map Task와 Reduce Task를 수행하며 작업 완료 상태를 JobTracker에 보고
- 주기적으로 Hearbeat 신호를 보내 JobTracker와 통신하며, 노드 상태를 알림
하지만, 이러한 구조는 JobTracker가 작업의 라이프 사이클 관리와 자원 관리를 모두 담당하여 병목 현상이 일어나게 되었고, 이외에도 다음과 같은 문제들이 발생되었다.
- SPOF(Single Point of Failure)
- JobTracker가 클러스터의 모든 작업 관리와 자원 할당을 담당하므로, JobTracker에 문제가 생기면 동작하지 않음
- 확장성 한계
- JobTracker가 자원 관리와 작업 스케줄링을 모두 처리하여, 클러스터 노드 수가 증가하면 JobTracker의 부하가 크게 증가
- 비효율적인 자원관리
- Task별로 자원을 고정적으로 할당하여 자원을 유연하게 활용하지 못하는 경우가 발생
- 유연성 부족
- MapReduce API를 구현한 작업만 처리할 수 있었기 때문에 SQL 기반 작업의 처리나, 인메모리 기반의 작업의 처리에 어려움
이를 해결하기 위해 Hadoop v2.0부터는 YARN(Yet Another Resource Negotiator)이 도입 되었다.
YARN (Yet Another Resource Negotiator)

YARN은 JobTracker의 기능을 분리하여 자원 관리는 Resource Manager(RM)와 Node Manager(NM), 작업의 사이클 관리 기능은 Application Master(AM)와 Container가 담당하도록 한다.
v1.0의 작업 단위는 Job이었지만, v2.0의 작업 단위는 application이다. YARN이 도입되면서 이름이 변경되었지만 동일하다.
YARN 아키텍처의 각 구성요소에 대해 설명하면 다음과 같다.
Resource Manager (RM)
- YARN의 마스터 서버로 하나 또는 이중화를 위해 두개의 서버에만 실행됨
- 클러스터 전체의 자원 관리와 할당을 담당
- Scheduler와 Application Manager라는 두 가지 구성 요소를 가짐
- Scheduler: 클러스터 내 모든 자원을 추적하며, 각 Application Master(AM)에게 자원을 할당
- Application Manager: 새로운 Application Master(AM)의 시작을 관리하고, application 생애주기를 조율
- 자원 관리만 담당하기 때문에 확장성과 안정성이 향상
Node Manager (NM)
- YARN의 워커 서버
- Resource Manager를 제외한 모든 서버에서 실행
- Resource Manager로부터 Container 실행 요청을 받아 작업을 실행
- Container의 라이프 사이클, 장애상황, 자원을 많이 사용하는지 등 모니터링하고 주기적으로 Resource Manager에 전달
Application Master (AM)
- 개별 application의 생애주기를 관리하는 역할을 담당
- Resource Manager로부터 자원을 요청
- Container에서 작업을 스케줄링 및 작업 상태 모니터링
- v1.0의 JobTracker와 달리 Application Master는 애플리케이션별로 독립적으로 실행되므로 SPOF 문제 해결
Container
- Node Manager가 관리하는 자원의 단위로, 애플리케이션 Task가 실행되는 실행 환경
- 각 컨테이너는 CPU, 메모리 등의 자원을 포함하며, Application Master가 요청한 자원에 따라 Node Manager에서 생성.
- Resource Manager가 CPU, 메모리와 같은 자원을 Node Manager에게 요청하여 Container를 생성하고, 그 안에서 Task를 실행
- Application이 실행되는 과정에서 여러 개의 Container가 사용될 수 있음
이러한 구조로 인해 자원 관리와 작업 관리를 분리하여 Hadoop v1.0에서 발생했던 확장성과 안정성 문제를 크게 개선했다.
Application Workflow in Hadoop YARN

YARN의 application workflow는 다음과 같다:
- Client가 application을 제출
- Resource Manager가 Application Manager를 시작하기 위해 Container를 할당
- Application Manager가 Resource Manager에 등록
- Application Manager 가 Resource Manager에게 Container를 요청
- Application Manager 가 Node Manager에게 Container를 시작하도록 알림
- Container에서 application code 실행
- Client가 Resource Manager/Application Manager에 연락하여 application 상태를 모니터링
- Application Manager가 Resource Manager에 등록을 취소
마무리
이번 글에서는 Hadoop의 핵심 구성 요소들인 MapReduce와 YARN에 대해 포스팅하였다.
지금 까지의 글을 정리해 보면 Hadoop은 HDFS로 대용량 데이터를 저장하고, MapReduce로 이를 효율적으로 처리하며 YARN으로 자원 관리와 작업 관리를 최적화하여 대규모 분산 환경에서도 높은 성능을 발휘한다.
이를 통해, Hadoop은 빅데이터 환경에서도 확장성, 안정성, 유연성을 가져 빅데이터 처리에서 대표적인 솔루션으로 자리 잡게 된 것 같다.
다음 글에서는 Hadoop 설치에 대한 내용을 포스팅할 예정이다.
'Data Engineering > Hadoop' 카테고리의 다른 글
| [Hadoop] Hadoop MapReduce를 이용한 Word Count 실습 (3) | 2024.12.03 |
|---|---|
| [Hadoop] Apache Hadoop 설치 (1) | 2024.12.03 |
| [Hadoop] HDFS란? (0) | 2024.12.01 |
| [Hadoop] Apache Hadoop 소개 (0) | 2024.11.24 |