

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 분산
- 딕셔너리
- 티스토리챌린지
- programmers
- 아파치 카프카
- 우선순위큐
- 빅데이터
- 코딩테스트
- 아파치 하둡
- DP
- docker
- Apache Spark
- 오블완
- 이진탐색
- 파이썬
- 프로그래머스
- 하둡
- 아파치 스파크
- leetcode
- Data Engineering
- Python
- Hadoop
- 분산처리
- heapq
- apache kafka
- Apache Hadoop
- 알고리즘
- 도커
- 리트코드
- Spark
- Today
- Total
래원
[Kafka] Kafka 데이터 흐름 이해하기: Partition과 Offset 본문

이번 글에서는 Kafka의 Partition과 Offset에 대해 공부한 내용을 정리하려고 한다.
본 글의 목차는 다음과 같다.
1. Events, Streams, and Topics
2. Partition
3. Partitioning
4. Partition 복제
5. Consumer의 데이터 읽기 방식: Pull
6. Commit/Offset
Events, Streams, and Topics

Partition에 대해 알아보기 전에, Event, Stream 그리고 Topic에 대해 먼저 알아보자
Event는 데이터의 단위이다. 이는 특정 작업이나 상태 변경을 나타낸다.
Stream은 Kafka에서 연속적으로 흐르는 Event들의 집합이다.
Topic은 데이터를 구분하기 위한 단위로 events stream이 이 Topic에 저장된다. Producer는 데이터를 특정 Topic에 게시하며, Consumer는 해당 Topic을 구독하여 데이터를 읽는다. 예를 들어, 뉴스 토픽에는 뉴스와 관련된 내용, 로그 토픽에는 로그와 관련된 내용을 저장한다.
위 그림을 보면 이들을 쉽게 이해할 수 있다.
Partition
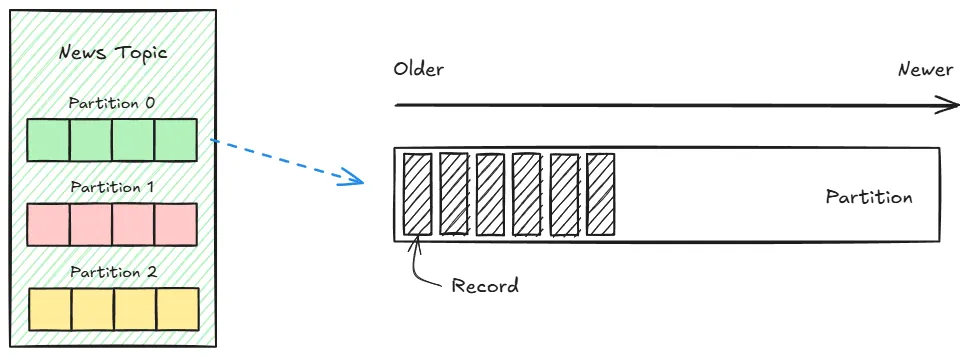
Kafka의 Topic은 여러 Partition으로 나뉘어 각 서버(Broker)에 분산되어 저장된다.
그렇다면 Partition은 뭘까? Partition을 정의하면 다음과 같다.
Topic에 속한 Record(데이터)를 실제 저장소에 저장하는 물리적 단위
각각의 Partition은 Append-only 방식으로 데이터를 기록하며, 순차적인 로그 구조를 유지한다.
Producer가 보낸 데이터는 Partition에 저장되며, Partition 내부에서 데이터는 FIFO(First-In-First-Out) 구조로 처리된다.
하지만 일반적인 큐와는 달리, 데이터를 처리하거나 삭제하지 않고 지정된 보존 기간 동안 데이터를 유지한다.
이러한 Partition의 갯수는 사용자가 직접 지정할 수 있지만, 제한 사항이 하나 있다.
Partition수를 늘릴 수는 있지만 줄일 수 는 없다는 것이다. 이는 Partition 구조가 데이터의 저장 및 소비 방식에 영향을 미치기 때문이다. Partition을 줄이는 경우 기존 데이터를 재분배해야 하며, 데이터 순서등을 보장하기 어려워질 수 있다.
따라서, 처음 Topic을 생성할 때는 적절한 Partition 수를 결정하는 것이 중요하다.

각 Partition의 모든 Record에는 고유한 Offset 값이 부여된다.
Offset은 Partition 내에서 Record의 위치를 나타내는 순차적인 숫자로, 이를 통해 Partition내의 데이터 순서를 보장한다.
위 그림에서 볼 수 있듯이, 각 Partition은 0부터 시작하는 Offset 값을 가지고 있으며, 새 데이터가 추가될 때마다 Offset이 1씩 증가한다.
Consumer는 이 Offset을 활용하여 데이터를 읽으며, 읽은 마지막 Offset 정보를 저장해두어 이후 처리 중단 시에도 이어서 데이터를 처리할 수 있다. 이는 뒤에서 더 설명할 예정이다.
Partitioning

그렇다면 Producer는 Topic에 데이터를 push할 때, 어느 Partition에 넣을까?
여기에는 Key 기반 Partition 결정 방식, Round-Robin 방식, 사용자 정의 방식의 크게 3가지 방법이 있다.
Key 기반 Partition 결정

Producer는 메시지에 Key를 설정할 수 있는데, 이 key를 해싱하여 Partition을 결정한다.
이는 동일한 Key를 가진 데이터는 항상 동일한 Partition에 저장된다. 예를 들어, 사용자 ID를 Key로 설정하면 해당 사용자의 모든 이벤트가 같은 Partition에 저장된다.
Round-Robin 방식 (Key가 없는 경우)

Key를 성정하지 않은 경우, Kafka는 Round-Robin 방식을 사용하여 Partition을 선택한다.
이는 Partition을 순차적으로 순회하면서 데이터를 분산한다. 따라서, 데이터를 균등하게 분산 시켜 부하를 최소화하는데 효과적이다.
사용자 정의 방식
Kafka는 Producer가 사용자 정의 Partitioner를 구현할 수 있도록 지원한다.
특정 조건에 따라 데이터를 특정 Partition에 저장해야하는 경우, 데이터의 부하 분산을 사용자 정의 방식으로 처리하려는 경우 등의 사용된다.
Partition 복제

Kafka는 고가용성을 위해 Partition을 복제하여 저장한다. 이를 통해 하나의 Broker가 장애를 일으켜도 다른 Broker에서 데이터를 사용할 수 있다. 예를 들어, 복제 수를 3으로 설정한 경우, 한 Partition의 3개의 복사본이 존재한다.
또한 복제 수를 N으로 설정할 경우, 1개의 리더(Leader)와 N-1개의 팔로워(Follower)로 나뉘게된다.
리더는 각 Partition의 모든 읽기와 쓰기 작업을 수행하고, 팔로워는 리더의 데이터를 복제받아 저장하는 역할을 한다. 즉, 읽기/쓰기 작업에는 관여하지 않과 리더의 데이터를 동기화하며 대기 상태에 있는다.
이를 통해, 리더가 장애를 일으켜도 Kafka는 자동으로 팔로워 중 하나를 새로운 리더로 선출한다. 즉, 복제수가 N일 경우 최대 N-1개의 장애까지 견딜 수 있다.
또한, Kafka는 Partition의 리더를 모든 Broker에 균등하게 분배한다. 이로써 특정 Broker에 부하가 물리지 않도록 하며, 시스템 성능을 최적화한다.
Consumer의 데이터 읽기 방식: Pull

Kafka에서 Consumer는 Pull을 사용하여 필요한 데이터를 직접 요청해 가져온다.
이렇게 하면 자신의 처리 속도에 맞춰 데이터를 가져오므로 과부하를 피할 수 있고, Consumer가 명시적으로 데이터를 가져오기 때문에 메시지 유실을 방지하고 안정적으로 데이터를 처리할 수 있다.

앞서 설명했듯 Kafka의 Partition은 Append-only 로그 방식으로 데이터를 저장하기 때문에, Consumer는 데이터를 쓰여진 순서대로 읽을 수 있다.
Consumer는 offset을 기반으로 데이터를 읽는다. 이 때, commit을 통해 offset 정보를 저장하는데, commit에는 자동 commit과 수동 commit이 있다.
자동 commit은 주기적으로 offset 정보를 자동으로 저장하는 방법이다. 이는 간편하지만, 메시지를 완전히 처리하기 전에 offset이 commit 될 수 있다는 단점이 있다.
수동 commit은 말그대로 메시지 처리가 완료된 후, 명시적으로 offset을 commit한다. 이는 데이터 처리의 신뢰성을 높이지만, 구현이 복잡할 수 있다.
예를 들어, consumer가 Partition에서 저장된 offset 6을 기준으로 데이터를 읽는다. 즉, 6번 record를 가져와 데이터를 처리한다. 데이터 처리가 완료되면, commit을 통해 offset 정보를 저장한다. 이는 kafka의 __consumer_offsets라는 내부 토픽에 기록되며 이후 consumer는 다음 offset (7)부터 데이터를 읽기 시작한다.
Commit/Offset

위 그림은 위 설명에 대해 보여준다.
Consumer가 poll()을 하면 이전에 commit한 offset이 있으면 그 offset 이후의 record를 읽어온다.
읽어온 다음 마지막 읽어온 record의 offset을 commit하여 저장한다. 이때, commit에는 앞서 설명했듯이 자동 commit과 수동 commit이 있다.
따라서, commit은 메시지가 성공적으로 처리되었음을 나타내며, 이후 consumer는 commit된 offset 다음부터 데이터를 읽는다. 만약 consumer가 중단되거나 장애가 발생해 다시 시작될 경우, Kafka는 마지막으로 commit된 offset에서부터 읽기 시작한다.
Kafka 클러스터 예시

마무리
이번 글에서는 Kafka의 Partition, Offset 그리고 Consumer가 어떻게 데이터를 가져오는지에 대해 정리해보았다.
Kafka의 이러한 구조 덕분에 높은 성능과 신뢰성을 유지할 수 있는 것 같다.
앞으로 Kafka를 사용할 때 어떤 방식으로 설계하고 최적화해야 할지 더 명확한 기준을 세울 수 있을 것 같다.
다음에는 Kafka 설치에 대한 글을 포스팅할 예정이다.
'Data Engineering > Kafka' 카테고리의 다른 글
| [Kafka] Apache Kafka 설치 (0) | 2025.01.08 |
|---|---|
| [Kafka] Zookeeper와 KRaft(Kafka Raft) (0) | 2025.01.07 |
| [Kafka] Apache Kafka 개요 (0) | 2024.12.28 |


