
이번 글에서는 Apache Kafka에 대해 간단히 소개할 예정이다.
본 글의 목차는 다음과 같다.
1. Kafka 등장 배경
2. What is Kafka
3. Kafka Architecture
4. Pub/Sub 모델
1. Kafka 등장 배경

`Kafka`에 대해 알아보기 전, 어떻게 `Kafka`가 등장했는지 알아보자
초기 Linkedin 운영 시에는 단방향 통신을 통해 연동했으며, 아키텍처가 복잡하지 않아 운영에 어려움이 없었다.
하지만, 시간이 지날수록 source, target application의 개수가 많아져 아키텍처가 거대해짐에 따라 데이터를 전송하는 라인이 위 그림과 같이 많이 복잡해졌다.
또한, 한쪽에 장애가 생기면 다른 한 쪽에도 전달되는 문제가 발생해 유지 및 보수가 어려워지면서 관리에 이슈도 생길 수 밖에 없었다.
이를 통해 Linkedin은 새로운 시스템을 만들기로 결정했고, 이것이 지금의 `Apache Kafka`가 되었다.
2. What is Apache Kafka?

`Kafka`를 정의해보면 다음과 같다.
대규모 데이터 스트리밍을 처리하는 오픈소스 분산 이벤트 스트리밍 플랫폼
`Kafka`는 Linkedin에서 개발되어 Apache Software Foundation에 기여되었으며, 현재는 데이터 파이프라인 및 실시간 데이터 처리의 핵심 기술로 널리 사용되고 있다.
이벤트 스트림을 `pub/sub 구조`를 통해 데이터를 지속적으로 가져오고 내보내며, 원하는 기간 동안 지속적으로 안정적이게 이벤트 스트림을 저장한다.
따라서, 대용량 데이터 처리 및 실시간 데이터 스트리밍에 적합하다.
3. Kafka Architecture
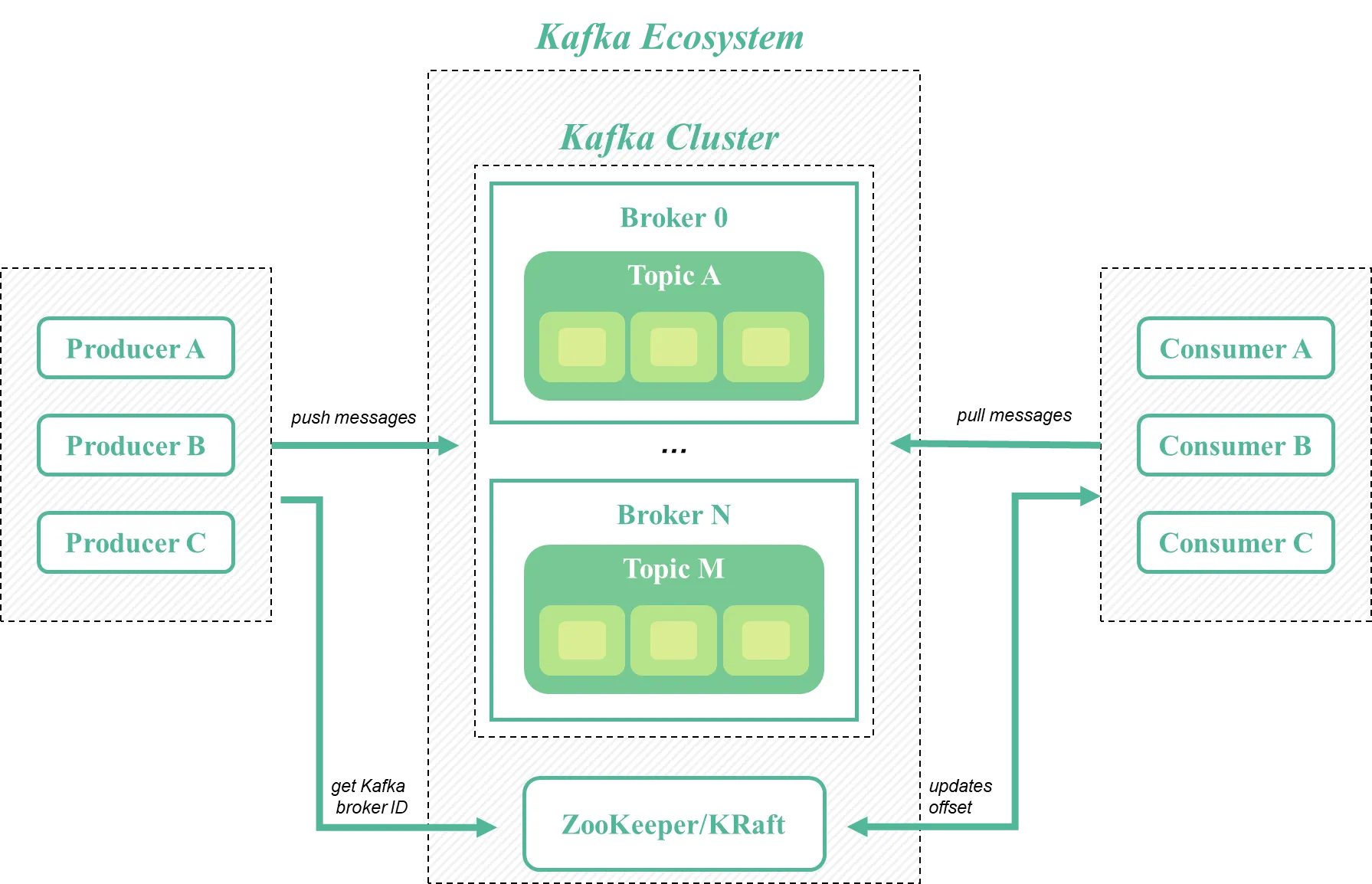
Kafka의 기본적인 구조는 위 그림과 같은데, 크게 `Producer`, `Consumer`, `kafka Cluster`, `Broker`, `Topic`, `Partition` 등의 구성 요소로 나뉘게 된다.
각각의 역할에 대해 간단히 소개하면 다음과 같다.
Broker
`Broker`는 Kafka Cluster를 구성하는 노드를 의미한다. `Producer`로 부터 데이터를 받아 `Topic`에 저장하고, `Consumer`에게 필요한 데이터를 전달하는 브로커 역할을 수행한다.
Kafka Cluster
`Kafka Cluster`는 여러 대의 `Broker`로 구성된 클러스터이다. 데이터를 저장, 관리, 전송하는 중심 역할을 한다.
Topic
`Topic`은 데이터를 카테고리별로 분류하기 위한 단위이다. `Producer`는 데이터를 특정 `Topic`에 게시하며, `Consumer`는 해당 `Topic`을 구독하여 데이터를 읽는다.
하나의 `Topic`은 여러 `Partition`으로 나뉘며 분산 처리 및 확장을 지원한다.
Partition
`Partition`은 `Topic`을 분할한 단위로 데이터가 물리적으로 저장되는 곳이다. 리더와 팔로워로 나뉘며, 리더 파티션은 데이터를 읽고 쓸 수 있는 주된 역할을 하며, 팔로워 파티션은 리더의 데이터를 복제하여 장애 발생 시 데이터 손실을 방지한다. 각 `파티션`은 하나의 Kafka 브로커에 저장되며, 클러스터 내에서 파티션을 분배하여 데이터의 병렬 처리를 가능하게 한다.
Producer
`Producer`는 데이터를 생성하여 `Kafka`로 전송하는 역할을 수행한다. 데이터를 특정 `Topic`에 게시하며, 이때 데이터는 메시지 단위로 전송한다.
Consumer
`Consumer`는 특정 `Topic`에서 메시지를 소비하여 처리하거나 저장하는 역할을 수행한다. `Consumer Group`을 통해 여러 `Consumer`들이 협력하여 데이터를 병렬로 처리할 수 있다.
Zookeeper/KRaft(Kafka Raft)
클러스터의 상태를 관리하고, 노드 간의 조정을 수행하는데 사용된다. 기존에는 `Zookeeper`가 사용되었으나, 최근 Kafka에서는 `Kafka Raft(KRaft)`를 도입되어 `Zookeeper` 대신 사용된다.
Kafka의 각 구성요소에 대해 간단하게만 소개하였는데, `Topic`과 `Partition`, `Zookeeper` 및 `KRaft`에 대한 내용은 추후에 별도의 포스팅을 통해 다룰 예정이다.
4. Publish/Subscribe(Pub/Sub) 모델
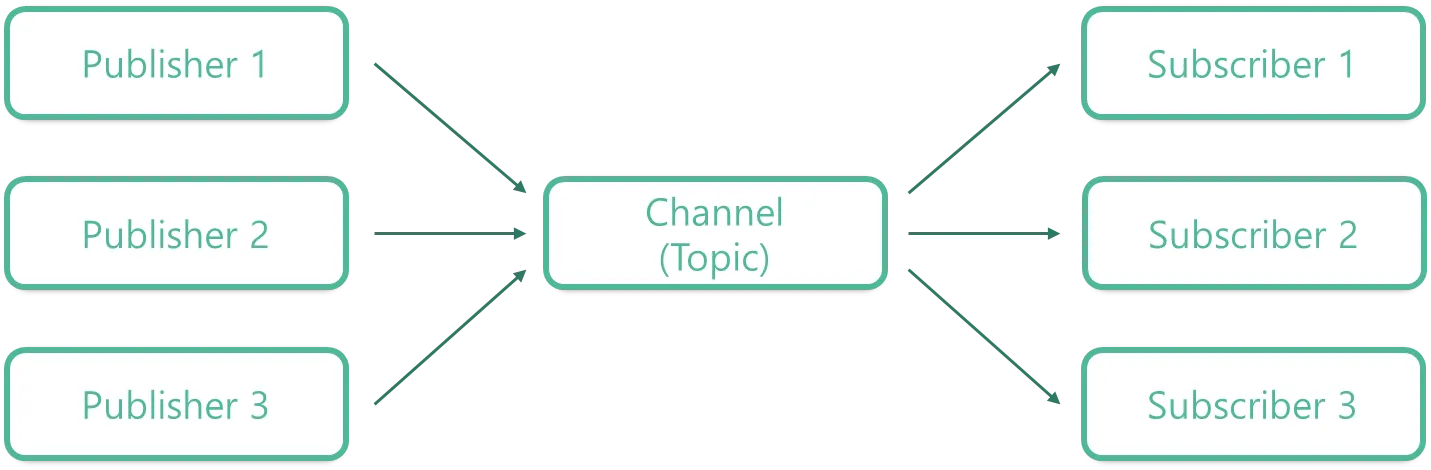
앞서 언급했듯이, `Kafka`는 `Pub/Sub 모델`을 따른다.
`Pub/Sub 모델`은 메시지 기반의 통신 패턴으로 주로 분산 시스템에서 사용된다. 이 모델은 두 가지 주요 역할이 있는데 `Publisher`와 `Subscriber`이다.
- `Publisher`는 메시지를 생성하고 이를 특정 `Channel(Topic)`에 게시하는 역할을 한다. `Publisher`는 메시지를 발행한 후, 메시지가 어떻게 처리될지에 대해 알지 못한다.
- `Subscriber`는 특정 `Channel(Topic)`을 구독하여 해당 `Channel(Topic)`에 게시된 메시지를 받아 처리하는 역할을 한다. `Subscriber`는 자신이 구독한 `Channel(Topic)`에 게시된 메시지를 실시간으로 받아서 사용할 수 있다.
이러한 `Pub/Sub 모델`은 다음과 같은 특징을 가진다.
- `비동기적 통신`: Publisher는 메시지를 게시한 후 즉시 다른 작업을 진행할 수 있다. 메시지의 처리 여부나 결과는 Subscriber에게 맡긴다.
- `확장성`: 여러 Subscriber가 동일한 Topic을 구독하고, Publisher는 다수의 Subscriber에게 동시에 메시지를 보낼 수 있어 확장성이 좋다.
`Kafka`에서 `Producer`는 Publisher 역할을 하고, `Consumer`는 Subscriber 역할을 한다.
즉, `Producer`는 데이터를 생성하여 `Topic`에 게시하고, `Consumer`는 해당 `Topic`을 구독하여 데이터를 처리한다.
`Producer`와 `Consumer`는 서로 독립적으로 동작하며, 새로운 `Consumer`를 추가하거나 여러 `Producer`가 데이터를 동시에 게시하는 등 다양한 확장 가능성을 가진다.
따라서, `Kafka`는 이러한 특성을 통해 대규모 분산 시스템에서 효율적으로 메시지를 처리하고 성능을 유지할 수 있다.
마무리
이번 글에서는 `Apache Kafka`에 대해 간단히 소개하였다.
확실히, `Kafka의 분산 아키텍처`, `Pub/Sub 모델`, `높은 처리량`, `확장성 및 내구성` 덕분에 다양한 산업 분야에서 실시간 데이터 처리와 이벤트 스트리밍의 핵심 플랫폼으로 자리잡고 있는 것 같다.
이번 글에서는 간단하게만 소개하였기 때문에, 다음 글에서는 `Topic`과 `Partition`을 비롯해 각각 구성요소에 대해 좀 더 자세히 다뤄볼 예정이다.
'Data Engineering > Kafka' 카테고리의 다른 글
| [Kafka] 간단한 Producer/Consumer 실습 (Java) (0) | 2025.01.10 |
|---|---|
| [Kafka] Apache Kafka 설치 (0) | 2025.01.08 |
| [Kafka] Zookeeper와 KRaft(Kafka Raft) (0) | 2025.01.07 |
| [Kafka] Kafka 데이터 흐름 이해하기: Partition과 Offset (0) | 2025.01.07 |