
이번 글에서는 Apache Spark 설치 과정을 소개할 예정이다.
큰 목차는 다음과 같다.
1. 버전 정보
2. SSH 설정
3. Spark 설치
4. 환경 변수 설정
5. Apache Spark 클러스터 구성
6. Spark 실행
7. Spark 종료
8. 마무리
버전 정보
본 글에서 사용하는 환경은 다음과 같다.
OS: Ubuntu 20.04
Java: openjdk-11-jdk
Hadoop: Hadoop 3.4.0
Spark: Spark 3.5.1
SSH 설정
Spark는 Hadoop과 마찬가지로 노드 간 통신과 협력이 필요하기 때문에 SSH 설정을 필수적으로 해야한다.
이미 되어 있다면 skip해도 된다.
먼저, 사용할 모든 노드의 /etc/hosts 파일에 사용할 노드들의 IP와 이름을 지정해준다.
$ sudo vim /etc/hosts # 사용할 모든 노드에서
<IP> <NAME>
<IP> <NAME>
.
.
.
<IP> <NAME>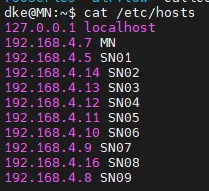
그리고 사용할 모든 노드에서 root로 접속해 /etc/ssh/sshd_config 파일을 수정해준다.
sudo su
vim /etc/ssh/sshd_config
PermitRootLogin no # yes로 변경
...
PasswordAuthentication no # yes로 변경

그 후 exit 명령어로 root 계정을 빠져나와 SSH를 재실행 해준다.
$ systemctl restart sshd
그런 다음 마스터 노드에서만 다른 노드들에 접근할 수 있게 키를 저장한다.
$ ssh-copy-id -i ~/.ssh/id_rsa.pub dke@SN01
$ ssh-copy-id -i ~/.ssh/id_rsa.pub dke@SN02
$ ssh-copy-id -i ~/.ssh/id_rsa.pub dke@SN03
$ ssh-copy-id -i ~/.ssh/id_rsa.pub dke@SN04
...
$ ssh-copy-id -i ~/.ssh/id_rsa.pub dke@SN09
만약 22번 포트를 사용하지 않는다면 명령어 마지막에 -p <Port> 을 붙여주면된다.
Spark 설치

https://spark.apache.org/downloads.html
Downloads | Apache Spark
Download Apache Spark™ Choose a Spark release: Choose a package type: Download Spark: Verify this release using the and project release KEYS by following these procedures. Note that Spark 3 is pre-built with Scala 2.12 in general and Spark 3.2+ provides
spark.apache.org
위 사이트에서 Spark를 다운 받을 수 있다.

본 글에서는 Spark 3.5.1을 사용했기 때문에 spark-3.5.1-bin-hadoop3.tgz 다운 링크를 복사해 wget 함수를 통해 받아왔다.
이 역시 사용할 모든 노드에서 수행해야 한다.
$ (sudo) wget https://dlcdn.apache.org/spark/spark-3.5.1/spark-3.5.1-bin-hadoop3.tgz
$ (sudo) tar -xvf spark-3.5.1-bin-hadoop3.tgz
#심볼릭 링크 생성
$ (sudo) ln -s spark-3.5.1-bin-hadoop3 spark
위 명령어들을 실행하면 위 그림과 같이 저장되어 있을 것이다.
환경 변수 설정
다음으로 환경 변수를 설정해주어야 한다.
이 역시 사용할 모든 노드에서 수행해야 한다.
# 모든 노드에서
sudo vim /etc/profile
# 추가
export SPARK_HOME=<Spark 설치 경로>
같은 방법으로 사용자환경 변수도 등록해야 한다.
#모든 노드에서
sudo vim ~/.bashrc
#추가
export SPARK_HOME=<Spark 설치 경로>
# 저장 후 나와서
source ~/.bashrc
잘 됐는지 확인하는 방법은 다음과 같다.
env | grep SPARK
Apache Spark 클러스터 구성
다음으로 사용할 클러스터 구성이다.
이는 마스터 노드에서만 진행한다.
cp <Spark 설치 경로>/conf/workers.template <Spark 설치 경로>/conf/workers
vim <Spark 설치 경로>/conf/workers
#localhost를 주석 처리한 후 사용할 노드의 이름을 넣어준다.
<node_name1>
<node_name2>
.
.
.
<node_namen>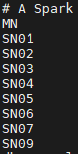
cp <Spark 설치 경로>/conf/spark-env.sh.template <Spark 설치 경로>/conf/spark-env.sh
vim <Spark 설치 경로>/conf/spark-env.sh
#추가
export SPARK_SSH_OPTS="-p <ssh port>"
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PYSPARK_PYTHON=python3
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export SPARK_MASTER_HOST=MN
HADOOP_CONF_DIR은 Hadoop 설정 파일 디렉토리를 Spark가 참조하도록 지정한다. Spark가 Hadoop HDFS와 연동하거나 YARN 클러스터를 사용할 때 필요하다.
Hadoop 설치 과정은 아래 링크에서 확인 가능하다.
PYSPARK_PYTHON=python3는 PySpark 작업에서 Python3 환경을 보장하기 위한 설정이다.
JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64은 Java 설치 경로를 Spark에게 알려주는 설정이다.
SPARK_MASTER_HOST=MN는 마스터 노드의 호스트 이름 또는 IP 주소를 지정한다.
따라서 이 설정들은 Spark가 여러 환경을 정상적으로 인식하고 활용할 수 있도록 돕는 역할을 한다.
Spark 실행
기본적인 설정은 끝났으니 이제 실행해보자
# 마스터 노드에서
.<Spark 설치 경로>/sbin/start-all.sh
# 실행 확인
curl localhost:8080
# 또는 직접 localhost:8080 접속
# 또는 포트포워딩 후 ip:8080 접속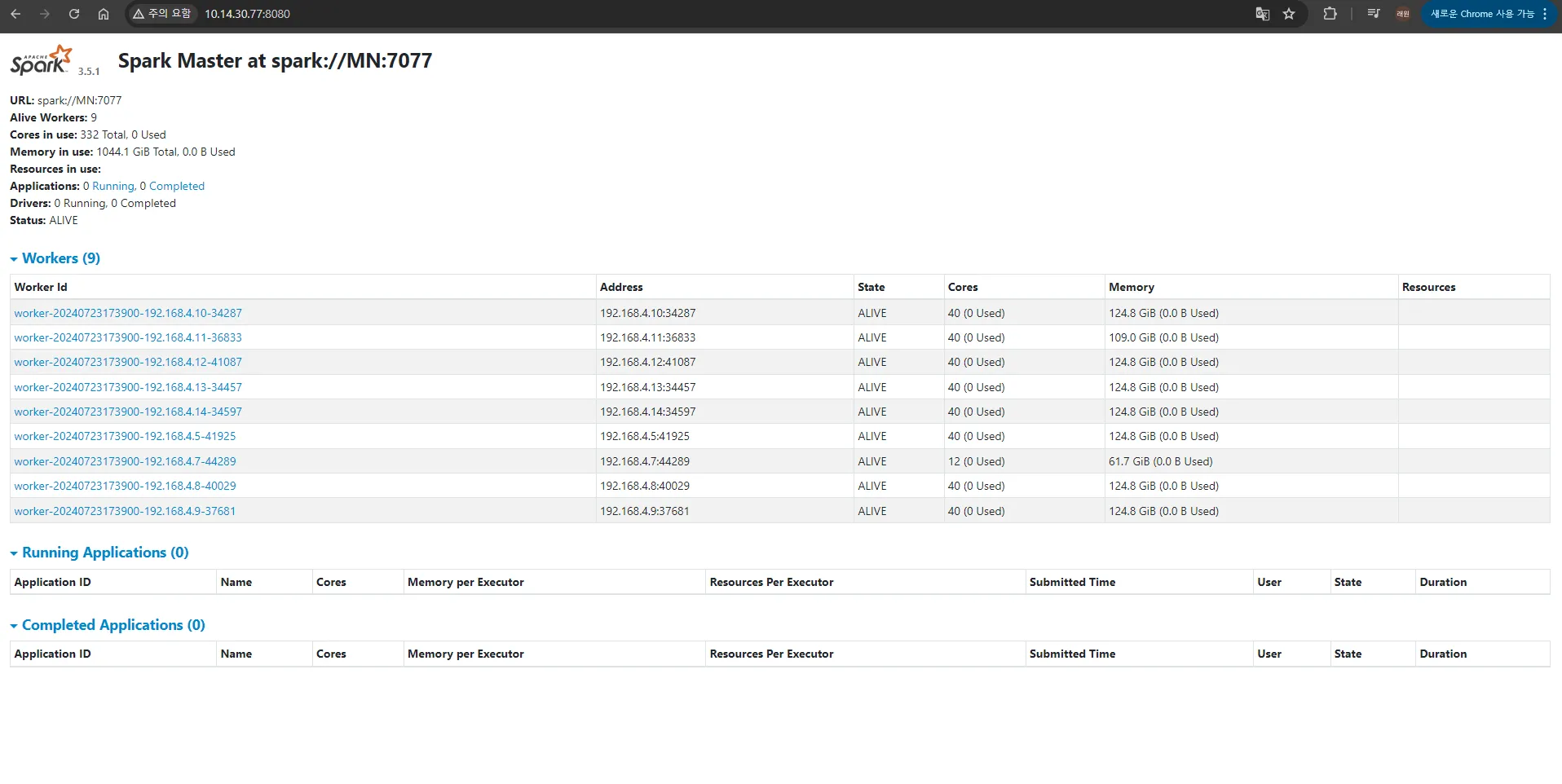
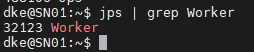
또한 jps를 통해 마스터 노드에 Master, 워커 노드들에는 Worker가 띄워져있는 것을 확인 가능하다.
MN

SN01 ~ SN09
Spark 종료
종료는 다음과 같이 할 수 있다.
# 마스터 노드에서
.<Spark 설치 경로>/sbin/stop-all.sh
마무리
이번 글에서는 Spark 설치 과정에 대해 소개 하였다.
Hadoop 설치에 비해 까다롭지는 않았지만, 그래도 쉽지 않은 여정이었던 것 같다.
다음에는 간단한 Spark SQL, SparkML 등 실습을 진행할 예정이다.
'Data Engineering > Spark' 카테고리의 다른 글
| [Spark] Zeppelin으로 SparkSQL 간단히 사용해보기 (1) | 2024.12.16 |
|---|---|
| [Spark] What is RDD, DataFrame, Dataset? (0) | 2024.12.09 |
| [Spark] Spark Ecosystem과 Spark Architecture (1) | 2024.12.06 |
| [Spark] Apache Spark(아파치 스파크) 개요 (1) | 2024.12.05 |