
이번 글에서는 RDD(Resilient Distributed Dataset), DataFrame, Dataset에 대해 정리하려고 한다.
Spark의 가장 큰 강점 중 하나가 데이터 처리 방식을 추상화한 위에 3가지를 제공한다는 점이다.
3가지의 도입 시기는 다음과 같다.
- RDD: spark 1.0
- DataFrame: spark 1.3
- Dataset: spark 1.6 (alpha version)
이제 각각이 무엇인지 알아보자
본 글의 목차는 다음과 같다.
1. RDD (Resilient Distributed Dataset)
1.1. What is RDD?
1.2. Transformation
1.3. Action
1.4. RDD 특징
2. DataFrame
2.1. DataFrame 등장 배경
2.2. What is DataFrame
2.3. DataFrame 특징
2.4. RDD vs. DataFrame
3. Dataset
3.1. What is Dataset
3.2. Dataset 특징
4. RDD vs. DataFrame vs. Dataset
5. 마무리
1. RDD (Resilient Dsitrubuted Dataset)

1.1. What is RDD?
RDD는 다음과 같다.
쉽게 복원이 되는, 탄력있는 분산 데이터
이는 Spark에서 데이터를 표현하는 가장 기본적인 데이터 추상화이며, 데이터를 여러 파티션으로 나눠 분산 환경에 병렬 처리할 수 있도록 설계 되었다.
RDD는 위 그림과 같이 `Transformation`과 `Action`이라는 두 가지 과정을 통해 데이터를 처리한다.
1.2. Transformation
이는 기존의 RDD를 변환하여 새로운 RDD를 생성하는 과정이다.
Transformation이 수행될 때마다 새로운 RDD가 생성되며 이는 DAG(Directed Acyclic Graph)의 형태를 구성하게 된다.
이 때, RDD는 변화가 있을 때마다 Lineage라는 기록으로 남기게 되는데 특정 RDD 정보가 유실될 경우, Lineage를 복기하여 자동 복구 가능하다.
Transformation은 lazy execution 방식으로 실제 데이터 연산 수행을 하지 않는다. → Action이 호출되면 데이터 연산 수행
주요 Transformation 함수에는 `map`, `filter`, `flatMap`, `reduceByKey` 등이 있다.
1.3. Action
이는 Transformation에서 생성된 실행 계획을 실제로 수행하여 결과를 반환하거나 저장하는 과정이다
즉, Action이 호출되면 Spark는 DAG를 실행하여 결과를 반환하거나 저장소에 데이터를 저장한다.
주요 Action 함수에는 `collect`, `count`, `reduce`, `saveAsTextFile` 등이 있다.
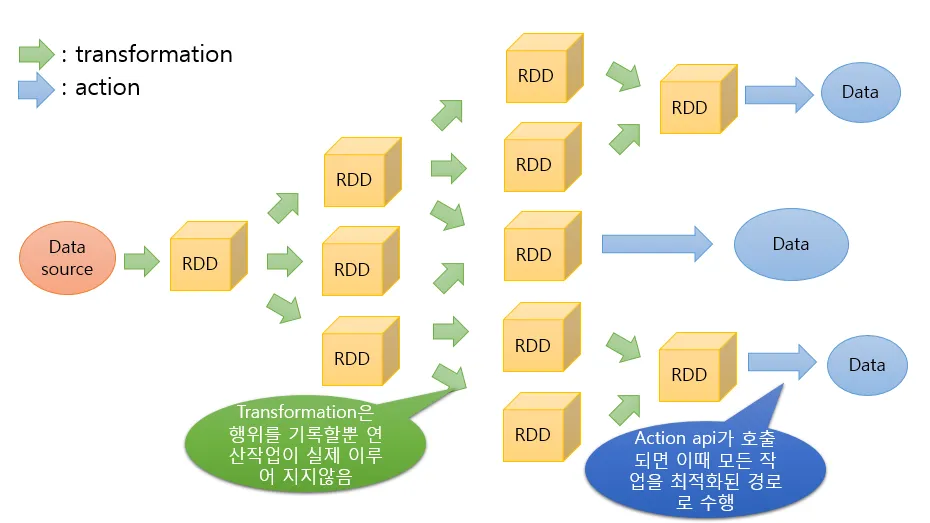
따라서, 정리해보면 Transformation은 실행 계획만 세우고 Action이 호출될 때 데이터 처리가 수행된다.
예를 들어, map이나 filter와 같은 Transformation 작업은 데이터를 즉시 변환하지 않고, Spark의 DAG에 작업 단계를 추가한다. 이후 collect나 count와 같은 Action이 호출되면 Spark가 DAG를 실행하여 결과를 계산한다.
1.4. RDD 특징
RDD의 특징은 다음과 같다.
- `불변성`
- RDD는 한 번 생성되면 변경되지 않는 대신 Transformation을 통해 새로운 RDD를 생성
- `분산 처리`
- 데이터를 여러 클러스터 노드에 분산하여 처리
- `저수준 API`
- map, filter, reduce와 같은 함수로 세부적인 데이터 연산을 제어할 수 있음
- `Lazy Execution`
- RDD는 실행 전 DAG를 생성하고 필요할 때 실행
- `Fault Tolerance`
- Lineage 정보를 유지하여 장애가 발생했을 때 손실된 데이터를 복구할 수 있음
2. DataFrame
2.1. DataFrame 등장 배경
DataFrame은 RDD의 다음과 같은 한계를 극복하기 위해 등장했다.
- RDD는 비구조화된 데이터를 처리하여 스키마 정보가 없어 데이터의 구조를 명시적으로 다룰 수 없음
- 저수준 API로 인해 많은 코드를 작성해야함
- Catalyst 옵티마이저와 같은 최적화 기능을 활용하지 못함
따라서, DataFrame은 RDD의 한계를 보완하여 더 효율적이고 직관적인 데이터 처리를 가능하게 한다.
2.2. What is DataFrame?
RDD의 한계를 극복하기 위해 설계된 2차원 데이터 형식으로, Schema 정보를 포함하여 데이터를 다룬다.
RDD보다 높은 수준의 API를 제공하며, SQL 쿼리와 유사한 방식으로 데이터를 처리할 수 있다.
Pandas의 DataFrame과 유사하지만, 같지는 않다.
2.3. DataFrame 특징
DataFrame의 특징은 다음과 같다.
- `구조화된 데이터`:
- 행과 열로 구성되며, 각각의 열에 대한 schema 정보를 포함
- `성능 최적화`
- Catalyst 옵티마이저를 통해 쿼리 성능을 최적화
- `높은 생산성`
- SQL 쿼리처럼 친숙한 API를 제공하며, 고수준 함수로 데이터를 쉽게 다룰 수 있음
- `내결함성`
- RDD와 마찬가지로 데이터 복구가 가능하며, 데이터 처리의 신뢰성을 제공
- `다양한 데이터 소스 지원`
- CSV, JSON, Parquet 등 다양한 데이터 소스와 포맷을 지원
2.4. RDD vs. DataFrame
# RDD 생성
data = [("Alice", 1), ("Bob", 2), ("Alice", 3), ("Bob", 4)]
rdd = sc.parallelize(data)
# RDD에서 Alice의 값만 합산
result = rdd.filter(lambda x: x[0] == "Alice").map(lambda x: x[1]).reduce(lambda a, b: a + b)# DataFrame 생성
data = [("Alice", 1), ("Bob", 2), ("Alice", 3), ("Bob", 4)]
df = spark.createDataFrame(data, ["name", "value"])
# DataFrame에서 Alice의 값만 합산
result = df.filter(col("name") == "Alice").groupBy("name").sum("value").collect()
위 코드를 보면 RDD는 확실히 코드가 상대적으로 복잡한 것을 확인할 수 있다.
하지만, DataFrame은 SQL 쿼리처럼 직관적인 API를 제공하여 데이터를 쉽게 다룰 수 있다.
또한, 데이터에 대한 schema 정보를 활용할 수 있기 때문에 데이터 구조를 명시적으로 다룰 수 있다는 장점이 있다.
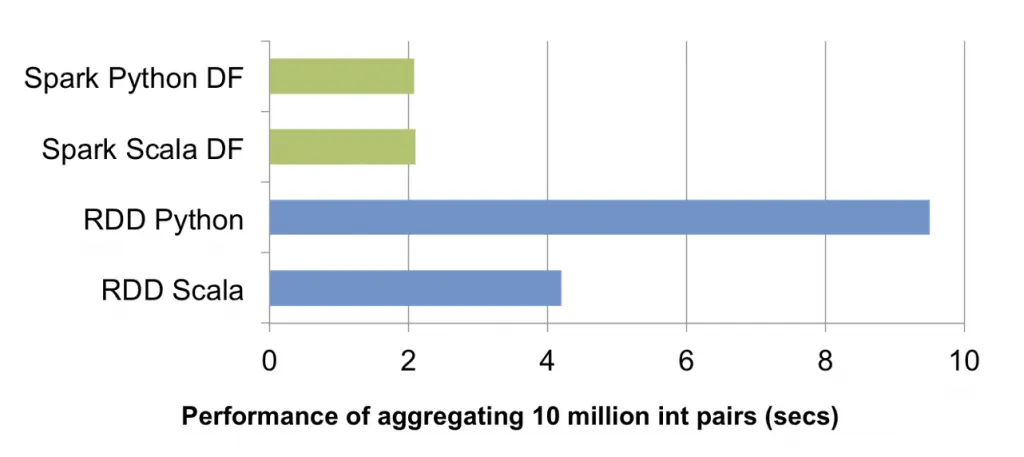
성능 역시 DataFrame이 RDD쿼리와 비교했을 때 좋은 것을 확인할 수 있다.
RDD를 사용했을 때 Python 쿼리 속도는 Scala에 비해 느린것을 확인할 수 있지만, DataFrame은 Catalyst 옵티마이저를 통해 scala, python의 성능이 동등하다.
이와 같이, RDD와 DataFrame은 동일한 데이터를 처리하더라도 코드의 복잡성과 성능에서 차이를 보인다.
3. Dataset
3.1. What is Dataset?
Dataset은 RDD와 DataFrame의 장점을 모두 제공하는 데이터 구조이다.
- RDD와 비슷한 방식으로 타입 안전성을 제공하며, 컴파일 타임에 오류를 검출할 수 있음
- DataFrame과 마찬가지로 고수준 API를 제공하여 SQL 쿼리처럼 직관적으로 데이터를 다룰 수 있음
데이터의 타입체크, 데이터 직렬화를 위한 인코더, Catalyst 옵티마이저를 지원하여 데이터 처리 속도를 더욱 증가시켰다.
Java와 Scala에서 사용 가능하다.
3.2. Dataset 특징
Dataset의 특징은 다음과 같다.
- `타입 안전성`
- Dataset은 타입 안전성을 제공하여 컴파일 타임에 오류를 잡을 수 있음
- 이는 DataFrame과 다르게 Dataset은 사용자 정의 객체나 강타입을 사용할 수 있기 때문에 코드 작성 시 더 강력한 타입 검사를 제공
- `불변성`
- Dataset은 RDD와 마찬가지로 불변성을 가짐
- 이는 데이터 변경이 불가능하며, 변환을 통해 새로운 Dataset을 생성하는 방식으로 동작
- `구조화된 데이터 처리`
- Dataset은 DataFrame처럼 구조화된 데이터를 처리할 수 있음
- 구조화된 데이터를 다룰 때, SQL이나 DataFrame API를 사용하여 데이터 처리 작업을 더 쉽게 가능
- `Catalyst 옵티마이저`
- DataFrame에서 제공하는 성능 최적화 기능인 Catalyst 옵티마이저를 Dataset에서도 사용 가능
- `직렬화와 인코더`
- Dataset은 데이터를 직렬화할 때 인코더를 사용하여 성능 향상
- `RDD와 DataFrame의 통합`
- Dataset은 RDD의 타입 안전성 특성과 DataFrame의 고수준 API, 성능 최적화 기능을 결합한 데이터 구조로, 둘의 장점을 동시에 제공
4. RDD vs. DataFrame vs. Dataset
| RDD | DataFrame | Dataset | |
| 타입 안정성 | X | X | O |
| API | Low level | High level | High level |
| 성능 최적화 | X | O | O |
| 사용 용도 | 세밀한 제어가 필요하고, 저수준 작업일 때 | SQL 쿼리 기반의 작업, 간편한 데이터 처리할 때 | 타입 안전성 및 고수준 작업이 필요할 때 |
| 성능 | 낮음 | 높음 | 높음 (타입 안전성 포함) |
RDD는 세밀한 제어가 필요한 경우 유용하고, DataFrame은 SQL 쿼리 스타일로 쉽게 데이터 처리가 필요할 때 적합하며, Dataset은 타입 안전성이 필요한 경우 유용하다.
Python 사용자에게는 DataFrame이 주로 사용되며, Scala 또는 Java 사용자들에게는 Dataset이 적합하다.
5. 마무리
이번 글에서는 Spark의 RDD, DataFrame, Dataset에 대해 정리해보았다.
다음 글에서는 Spark 설치에 대해 포스팅할 예정이다.
'Data Engineering > Spark' 카테고리의 다른 글
| [Spark] Zeppelin으로 SparkSQL 간단히 사용해보기 (1) | 2024.12.16 |
|---|---|
| [Spark] Apache Spark 설치 (2) | 2024.12.09 |
| [Spark] Spark Ecosystem과 Spark Architecture (1) | 2024.12.06 |
| [Spark] Apache Spark(아파치 스파크) 개요 (1) | 2024.12.05 |