

난이도: Lv.3
문제 설명
개발팀 내에서 이벤트 개발을 담당하고 있는 "무지"는 최근 진행된 카카오이모티콘 이벤트에 비정상적인 방법으로 당첨을 시도한 응모자들을 발견하였습니다. 이런 응모자들을 따로 모아 불량 사용자라는 이름으로 목록을 만들어서 당첨 처리 시 제외하도록 이벤트 당첨자 담당자인 "프로도" 에게 전달하려고 합니다. 이 때 개인정보 보호을 위해 사용자 아이디 중 일부 문자를 '*' 문자로 가려서 전달했습니다. 가리고자 하는 문자 하나에 '*' 문자 하나를 사용하였고 아이디 당 최소 하나 이상의 '*' 문자를 사용하였습니다.
"무지"와 "프로도"는 불량 사용자 목록에 매핑된 응모자 아이디를 제재 아이디 라고 부르기로 하였습니다.
예를 들어, 이벤트에 응모한 전체 사용자 아이디 목록이 다음과 같다면
| 응모자 아이디 |
| frodo |
| fradi |
| crodo |
| abc123 |
| frodoc |
다음과 같이 불량 사용자 아이디 목록이 전달된 경우,
| 불량 사용자 |
| fr*d* |
| abc1** |
불량 사용자에 매핑되어 당첨에서 제외되어야 야 할 제재 아이디 목록은 다음과 같이 두 가지 경우가 있을 수 있습니다.
| 제재 아이디 |
| frodo |
| abc123 |
| 제재 아이디 |
| fradi |
| abc123 |
이벤트 응모자 아이디 목록이 담긴 배열 user_id와 불량 사용자 아이디 목록이 담긴 배열 banned_id가 매개변수로 주어질 때, 당첨에서 제외되어야 할 제재 아이디 목록은 몇가지 경우의 수가 가능한 지 return 하도록 solution 함수를 완성해주세요.
제한 사항
- user_id 배열의 크기는 1 이상 8 이하입니다.
- user_id 배열 각 원소들의 값은 길이가 1 이상 8 이하인 문자열입니다.
- 응모한 사용자 아이디들은 서로 중복되지 않습니다.
- 응모한 사용자 아이디는 알파벳 소문자와 숫자로만으로 구성되어 있습니다.
- banned_id 배열의 크기는 1 이상 user_id 배열의 크기 이하입니다.
- banned_id 배열 각 원소들의 값은 길이가 1 이상 8 이하인 문자열입니다.
- 불량 사용자 아이디는 알파벳 소문자와 숫자, 가리기 위한 문자 '*' 로만 이루어져 있습니다.
- 불량 사용자 아이디는 '*' 문자를 하나 이상 포함하고 있습니다.
- 불량 사용자 아이디 하나는 응모자 아이디 중 하나에 해당하고 같은 응모자 아이디가 중복해서 제재 아이디 목록에 들어가는 경우는 없습니다.
- 제재 아이디 목록들을 구했을 때 아이디들이 나열된 순서와 관계없이 아이디 목록의 내용이 동일하다면 같은 것으로 처리하여 하나로 세면 됩니다.
입출력 예
| user_id | banned_id | result |
| ["frodo", "fradi", "crodo", "abc123", "frodoc"] | ["fr*d*", "abc1**"] | 2 |
| ["frodo", "fradi", "crodo", "abc123", "frodoc"] | ["*rodo", "*rodo", "******"] | 2 |
| ["frodo", "fradi", "crodo", "abc123", "frodoc"] | ["fr*d*", "*rodo", "******", "******"] | 3 |
입출력 예에 대한 설명
입출력 예 #1
문제 설명과 같습니다.
입출력 예 #2
다음과 같이 두 가지 경우가 있습니다.
| 제재 아이디 |
| frodo |
| crodo |
| abc123 |
| 제재 아이디 |
| frodo |
| crodo |
| frodoc |
입출력 예 #3
다음과 같이 세 가지 경우가 있습니다.
| 제재 아이디 |
| frodo |
| crodo |
| abc123 |
| frodoc |
| 제재 아이디 |
| fradi |
| crodo |
| abc123 |
| frodoc |
| 제재 아이디 |
| fradi |
| frodo |
| abc123 |
| frodoc |
✏️ Solution(솔루션)
case = []
cases = []
def recursion(start, end, available_based_len_bid, check):
global case
global cases
if start == end:
cases.append(case[:])
return case
for i in range(start, len(available_based_len_bid)):
for j in range(len(available_based_len_bid[i])):
if check[available_based_len_bid[i][j]] != True:
case.append(available_based_len_bid[i][j])
check[available_based_len_bid[i][j]] = True
case = recursion(start+1, end, available_based_len_bid, check)
check[available_based_len_bid[i][j]] = False
if len(case) != 0: case.pop()
return case
def solution(user_id, banned_id):
global cases
available_based_len_bid = [[] for _ in range(len(banned_id))]
check_dic = {}
answer = []
for idx, bi in enumerate(banned_id):
not_star = len(bi) - bi.count('*')
for ui in user_id:
cnt = 0
if len(ui) == len(bi):
for u, b in zip(ui, bi):
if u == b: cnt+=1
if cnt == not_star:
available_based_len_bid[idx].append(ui)
check_dic[ui] = False
recursion(0, len(banned_id), available_based_len_bid, check_dic)
for c in cases:
sc = sorted(c)
if len(set(c)) == len(banned_id) and sc not in answer:
answer.append(sc)
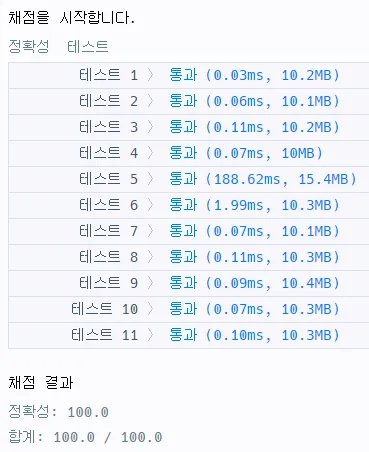
return len(answer)실행 결과
코드 설명
일단 이 문제는 경우의 수를 찾는 문제였다.
따라서 각 banned_id에 해당하는 user_id를 아래 그림과 같이 저장해주었다.

그렇다면 이제 얘네 가지고 경우의 수를 구하면 된다.
내 코드는 다음과 같이 동작한다. 인풋 데이터가 아래와 같을 때 그 아래 그림처럼 동작한다.
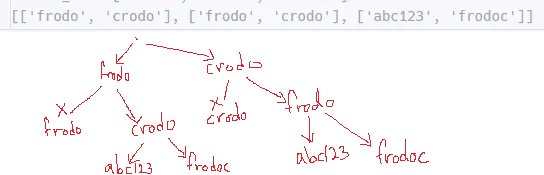
간단히 설명하면 첫번째 단어부터 시작해서 다음 단어를 보고 이미 방문한 단어면 넘어가고 아니면 다시 다음 단어를 보고 마지막 단어까지 왔으면 지금 까지의 단어들을 cases에 저장하는 코드이다
동작한 후 cases를 확인해보면 아래 그림과 같다. 위에 그림과 결과가 같은 것을 확인해볼 수 있다.

이렇게 마무리할 수 있으면 좋겠지만, 또 해결 해야 할 것이 있다.
예를 들어 위에 그림에서 {frodo, crodo, frodoc} 이랑 {crodo, frodo, frodoc}은 순서만 다르지 같은 애들로만 이루어져 있다. 따라서 같은 경우의 수로 봐야한다는 것이다.
따라서 이를 어떻게 해결할까 하다가 저것들을 다 정렬 시켜 해결하였다.
각 정렬 시킨 리스트를 answer에 append하고 만약 이 정렬된 리스트가 이미 answer에 있다? 그러면 아래와 같이 그냥 넘어가는 코드를 작성햇다.

for c in cases:
sc = sorted(c)
if sc not in answer:
answer.append(sc)
여기까지 왔으니 마지막으로 answer의 길이만 return해주면 우리가 원하는 결과를 얻을 수 있다.
'알고리즘 > 프로그래머스' 카테고리의 다른 글
| [Programmers] 베스트앨범 - Python (0) | 2024.11.26 |
|---|---|
| [Programmers] 오픈채팅방 (0) | 2024.11.24 |
| [Programmers] 프렌즈4블록 - Python (1) | 2024.11.20 |
| [Programmers] 등굣길 - Python (0) | 2024.11.17 |
| [Programmers] 야근 지수 - Python (1) | 2024.11.16 |